
By 2026, the phrase "Data is the new oil" has evolved. We now know that raw data, like crude oil, is useless—and even a liability—unless it is refined.
If Data Analytics is the "dashboard" that tells you where your car is going, Data Engineering is the engine, the fuel line, and the exhaust system that makes the car move in the first place. Without a solid engineering foundation, your AI models hallucinate, your Power BI reports lag, and your business decisions are based on "dirty" information.
What Exactly is Data Engineering?
At its core, Data Engineering is the practice of designing and building systems that collect, transform, and store data. It is the "plumbing" of the digital world. While a Data Scientist asks, "What does this data mean?", a Data Engineer asks, "How do I get this data here reliably, securely, and in real-time?"
The 3 Stages of a Modern Data Pipeline
In 2026, the standard "ETL" (Extract, Transform, Load) has shifted toward more flexible architectures. Here are the three critical stages every business must master:
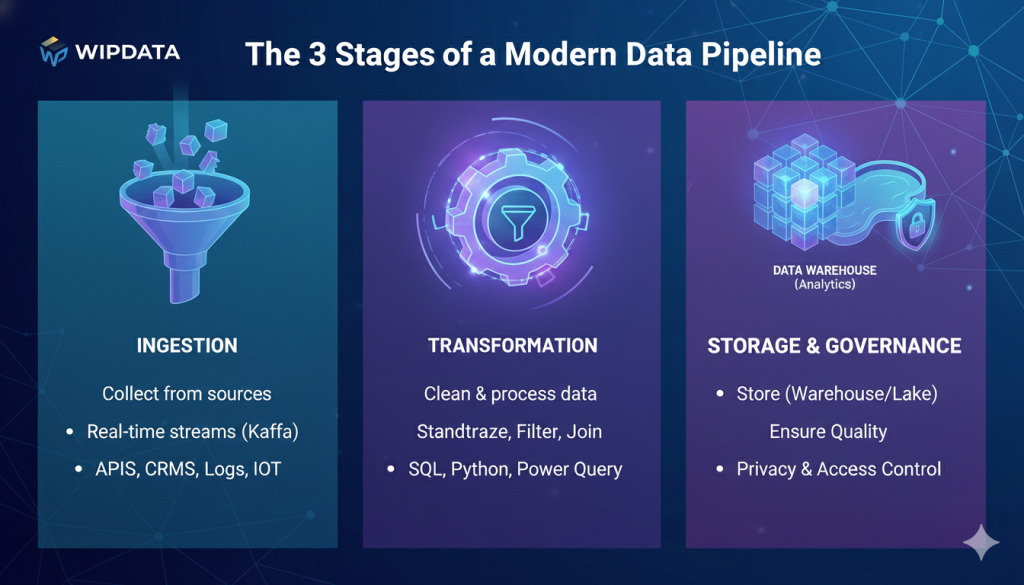
1. Ingestion: The Gathering
This is the process of pulling data from various sources—your CRM (like Salesforce), your website logs, IoT sensors, or social media APIs.
- The 2026 Twist: We are moving away from daily "batches." Modern ingestion happens in real-time using tools like Apache Kafka or Azure Event Hubs, ensuring your data is fresh the second it’s created.
2. Transformation: The Cleaning
Raw data is messy. It has duplicates, missing values, and inconsistent formats. Transformation is where the "refining" happens. Data engineers use SQL or Python to:
- Standardize date formats.
- Filter out "noise" or bot traffic.
- Join different datasets together (e.g., linking a customer’s email from your newsletter to their purchase history).
3. Storage & Governance: The Library
Once cleaned, the data needs a home.
- Data Warehouses (e.g., Snowflake, BigQuery): Best for structured business reporting.
- Data Lakes (e.g., Azure Data Lake): Best for storing massive amounts of raw, unstructured data for AI training.
- The Goal: Governance. In 2026, you don't just store data; you must tag it for privacy compliance (GDPR/PDPA) and ensure only the right people have the "key."
Why You Can’t Ignore This in 2026
Businesses that invest in robust data engineering see 60% faster resolution times when data issues occur and are the only ones capable of running "Agentic AI"—autonomous agents that actually do work for you based on your company's data.
The WIPDATA Takeaway
You don't need a team of 50 engineers to start. You need a clean strategy. Start by identifying your most valuable data source and building a simple, automated pipeline to get it into a dashboard.
Ready to build your first pipeline? Keep following our Q1 Data series. Next week, we’re showing you how to take this engineered data and turn it into a visual masterpiece using Power BI.